
本文旨在了解两种微调大型语言模型方法之间的差异:完全微调和低秩自适应 (LoRA)。这两种方法都用于将预训练模型适应特定的下游任务,但它们却有所不同。
微调(Fine-tuning)是将经过预训练的大语言模型应用于下游任务的关键范例。最近,低秩自适应 (LoRA) 等方法已被证明可以在各种任务上达到完全微调模型的性能,同时可训练参数的数量却大大减少。
这就提出一个问题,即它们学到的解决方案真的等效吗?
带着这一疑问,来自 MIT 的研究者在论文《 LORA VS FULL FINE-TUNING: AN ILLUSION OF EQUIVALENCE 》中进行了深入探讨。

论文地址:https://arxiv.org/pdf/2410.21228v1
作者通过分析预训练模型权重矩阵的光谱特性来研究不同的微调方法如何改变模型。
研究发现,完全微调与 LoRA 产生的权重矩阵奇异值分解结构有显著不同,并且经过微调后的模型在面对超出适应任务分布的测试时也显示出不同的泛化行为。
特别是,LoRA 训练的权重矩阵中出现了称为「侵入维度(intruder dimensions)」的新的高秩奇异向量,而在完全微调中则不会出现这种情况。
这些结果表明,即使在微调分布上表现相同,但使用 LoRA 和完全微调更新的模型访问参数空间的不同部分。
作者通过研究 LoRA 微调模型中出现侵入维度的原因、它们为什么不受欢迎,以及如何最小化这些效果来展开研究。
最后,作者给出了以下几点观察:
首先,LoRA 和完全微调在结构上产生不同的参数更新,这种差异由侵入维度的存在产生的。这些侵入维度是奇异向量,具有较大的奇异值,并且与预训练权重矩阵中的奇异向量近似正交。相比之下,完全微调模型在光谱上与预训练模型保持相似,不包含侵入维度。
其次, 从行为上看,与完全微调相比,具有侵入维度的 LoRA 微调模型会忘记更多的预训练分布,并且表现出较差的稳健连续学习能力:具有侵入维度的 LoRA 微调模型在适应任务分布之外不如完全微调模型,尽管分布准确度相当。
最后, 即使在目标任务上低秩 LoRA 表现良好,但更高秩的参数化可能仍然是可取的。低秩 LoRA(r ≤ 8)适合下游任务分布,完全微调和高秩 LoRA(r = 64)让模型泛化能力更强、自适应能力更加鲁棒。然而,为了利用更高的秩,LoRA 更新模型必须是秩稳定的。
沃顿商学院副教授 Ethan Mollick 对此评论道:事实证明,使用 LoRA 定制通用 LLM(Apple 调优其设备内置模型的方式),对 LLM 的限制远大于微调,因为它们失去了一些泛化能力。原因是 LoRA 增加了不祥的侵入维度。

LORA 和完全微调模型的差异
本文采用神经网络参数的奇异值分解 SVD 来理解微调对预训练权值的变化。
特别是,本文测量了用 LoRA 微调过的权重矩阵中的奇异向量或完全微调过的权重矩阵中奇异向量映射到预训练权重中的奇异向量的程度,使用它们的余弦相似性。这些关系如图 1 和图 3 所示,颜色表示预训练和微调奇异向量之间的余弦相似度。

图 2 (b) 中观察到,LoRA 和完全微调的奇异向量与预训练奇异向量的相似度非常不同:与完全微调相比,使用 LoRA 微调的模型的奇异向量与预训练奇异向量的平均余弦相似度似乎要低得多。
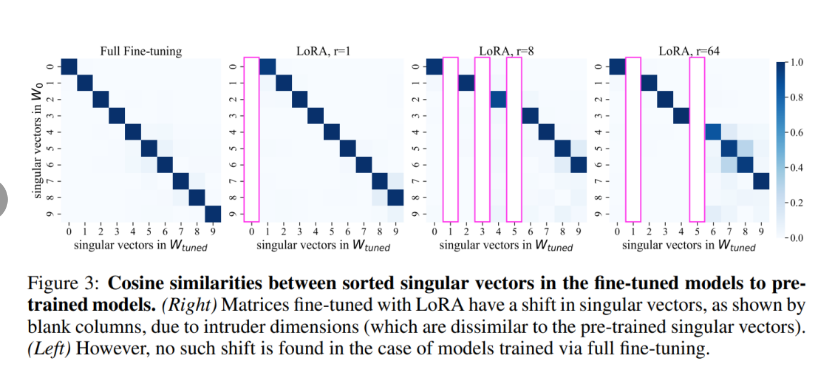
图 2 (b) 中左下角有一个唯一的红点,作者将这些新维度命名为侵入维度,其正式定义如下:

LoRA 微调模型包含高秩侵入维度,而完全微调的模型则不包含。为了量化特定权重矩阵的侵入维度集的大小,作者使用图 4 所示的算法。

即使在 LoRA 微调模型学习效果不如完全微调的任务中,侵入维度也存在。
观察图 5b、5c 和 5d,我们可以清楚地看到,即使 LoRA 的 r=256,高秩奇异向量集中仍出现侵入维度。重要的是,当 r=2048 时没有侵入维度,而是展示了与完全微调非常相似的曲线。这支持了早先的发现:随着秩增加超过一个阈值,侵入维度会消失,LoRA 开始趋向于与完全微调相似。

即使使用满秩矩阵执行 LoRA,完全微调更新也比 LoRA 更新具有更高的有效秩。如图 6 所示,可以观察到完全微调解决方案的有效秩明显高于通过 LoRA 学习到的解决方案的有效秩,即使 LoRA 具有更高的秩。

LORA 和完全微调之间的行为差异
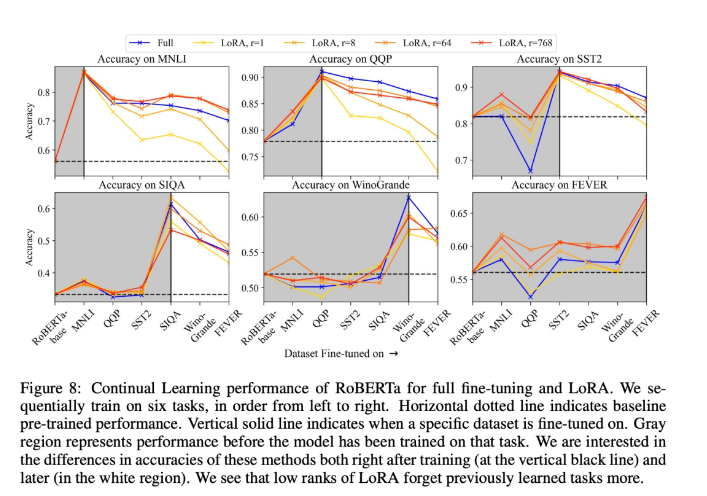
在较低秩,LoRA 在持续学习过程中的适应能力较差,会忘记更多之前的任务。该研究在多个任务上按顺序训练 RoBERTa,并测量学习新任务时性能的变化程度。
该研究使用与之前相同的训练方案、数据集,但在持续学习环境中使用以下数据集(按顺序)进行微调:MNLI、QQP、SST-2、SIQA、Winogrande、FEVER。在序列中某个数据集上进行训练后,将 LoRA 权重合并到模型中,并在下一个任务训练之前重新初始化,以便不受之前任务的影响。
在对特定任务进行训练后,该研究对所有任务进行测试,对于每个任务,在测试测试集之前分别重新训练分类头。这能够检查模型在这些任务上表现如何,而无需实际更改模型本身。
结果如图 8 所示。虽然 LoRA 最初与完全微调的性能相当,但较小的 LoRA 秩在持续学习过程中始终表现出更大的性能下降。特别是,对于前三个训练数据集,当 r = 1 时 LoRA 的性能下降到预训练基线以下。随着 LoRA 秩的提高,我们可以看到这种遗忘行为减少,并且更接近于完全微调,甚至在完成持续学习后在 MNLI 上的遗忘也更少。
整体情况是微妙的:虽然在某些情况下,LoRA 似乎忘记得较少,但对于某些任务(以及某些秩)事实上,LoRA 可能会忘记更多。
对于微调到等效测试精度的 LoRA 模型,可以看到一条 U 形曲线,该曲线标识了适合下游任务的最佳等级,同时最小程度的忘记了预训练分布。
图 9 报告了测量的伪损失分数。可以看到完全微调和 r = 768 时的 LoRA 之间呈现 U 形趋势。
相对于完全微调,低秩(r = 1)和高秩(r = 768)都会导致预训练分布的遗忘更大,而对于 r = 64,遗忘较少。也就是说:当 r = 1 时,使用 LoRA 微调的模型受到侵入维度的影响,并且似乎比没有侵入维度的 r = 64 有更多的遗忘。然而,当 r = 768 时,使用 LoRA 微调的模型也表现出更糟糕的遗忘,这表明由于过度参数化,它们对适应任务过度拟合。当 r = 8 和 r = 64 时,遗忘量少于完全微调。

