
在工业场景中,往往会利用检索技术来为大语言模型添加一些来自外部数据库的知识文档,从而增强大语言模型的回复可信度。一般来说,RAG 被公认是最有效的为 LLM 注入特定领域知识的方式。
然而,RAG 也有其不足之处。通常来说,在实际应用中,为确保能召回包含正确知识的文档,对于每个用户的查询,会检索多个文档(一般在 5 到 30 个之间),并把这些文档整合到输入提示中供大语言模型处理。这样一来,输入提示的序列长度增加,使得推理效率大幅降低。具体来讲,以首次生成标记的时间(TTFT)来衡量,RAG 大语言模型的推理延迟比非 RAG 大语言模型高很多。
由于数据库中同一文档经常会被不同 query 召回,大家很自然的会想到:是否能够把已经算好的文档表示(KV states)存在缓存中,以供二次使用?很遗憾, 由于自回归注意力机制的限制,大语言模型中每个文档的 KV States 都与上下文相关,所以遇到新的 query 时,模型必须重新编码 KV states 才能确保准确预测。
最近,论文《Block-Attention for Efficient RAG》为检索增强 (RAG) 场景实现了一种块状注意力机制,Block-Attention,通过分块独立编码检索到的文档,使得模型无需重复编码计算已经在其他 query 中已经见过的文档,从而实现线上推理效率的有效提升。在实验中,该方法能够让使用 RAG 技术的模型与不使用 RAG 的模型有几乎一样的响应速度。同时,该方法甚至还能略微提升在 RAG 场景下的模型准确率。

论文标题:Block-Attention for Efficient RAG
论文地址:https://arxiv.org/pdf/2409.15355
如下图所示,该方法把整个输入序列分成若干个 block,每个 block 独立计算其 KV States,只有最后一个 block 能够关注其他 blocks(在 RAG 场景中,最后一个 block 即用户的输入)。在 RAG 场景中,block-attention 让模型不再需要重复计算已经在其他 query 中见过的文档。
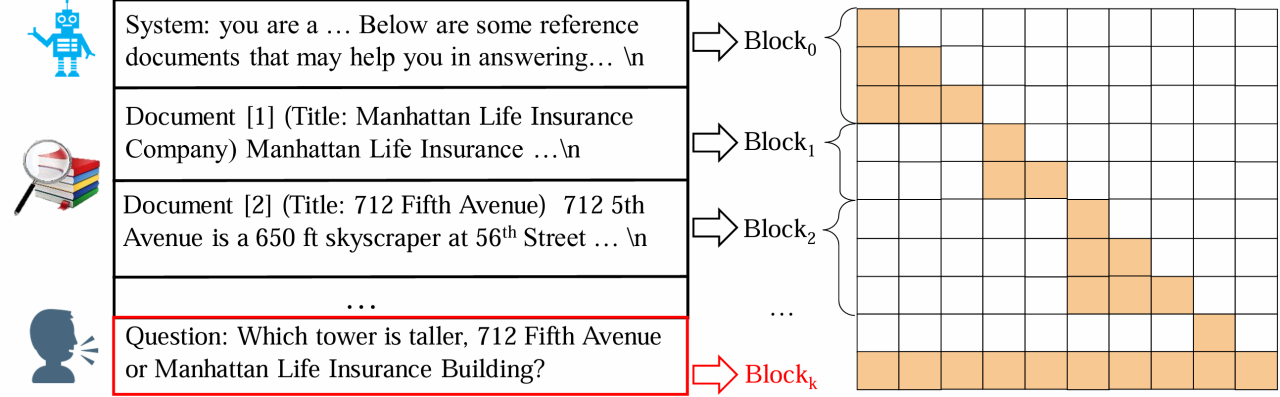
Block-Attention 的实现并不复杂:1)独立编码除最后一个 block 以外的所有 blocks;2)为每个 blocks 重新计算位置编码;3)将所有 blocks 拼接在一起,并计算最后一个 block 的 KV State。然而直接把模型不加任何修改的从 self-attention 切换到 block-attention 会导致大语言模型懵圈,毕竟模型在训练阶段从来没见过 block-attention 方式编码的输入。一个量化的对比是,直接切换为 block-attention 会让 Llama3-8B 在四个 RAG 数据集上的平均准确率由 67.9% 下降至 48.0%。
为了让模型适应 block-attention,作者们对模型进行了进一步微调,作者们发现在 100-1000 步微调之后,模型就能快速适应 block-attention,在四个 RAG 数据集上的平均准确率恢复至 68.4%。另外,block-attention 方式的模型在 KV cache 技术的帮助下,能达到与无 RAG 模型相似的效率。在用户输入长度为 50 而 prompt 总长度为 32K 的极端情况下,block-attention model 的首字延时(Time To First Token, TTFT)和首字浮点运算数(FLOPs To Frist Token, (FLOPs-TFT)分别能降低至 self-attention model 的 1.3% 和 0.2%,与无 RAG 模型的效率基本持平。
推理流程
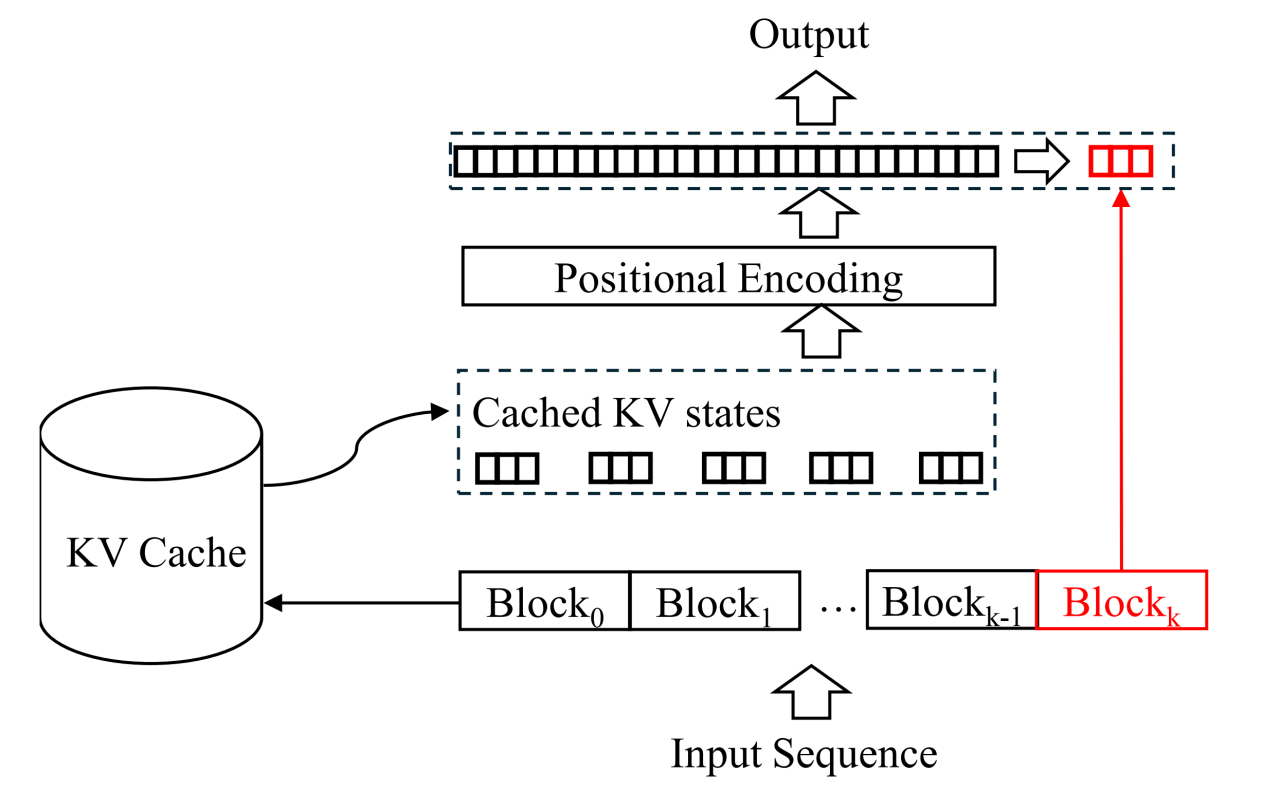
关于 block-attention 的实现和详细推导,读者们请移步原文,这里主要介绍 block-attention 模型的推理流程。如下图所示,首先从缓存中查询并提取前 K 个 block 的 KV states。然后,根据每个 block 在输入序列中的位置,作者们对每个 block 的位置编码进行了重新计算。具体的操作过程详见论文的公式 3。最后,根据前 k-1 个 KV States 计算最后一个数据块的键值状态以及模型的输出。
实验结果
在实验中,作者们主要想探究两个问题的答案:1)在 RAG 场景中,block-attention 模型能否达到与自 self-attention 相同的准确率?2)block-attention 对效率的提升有多大?
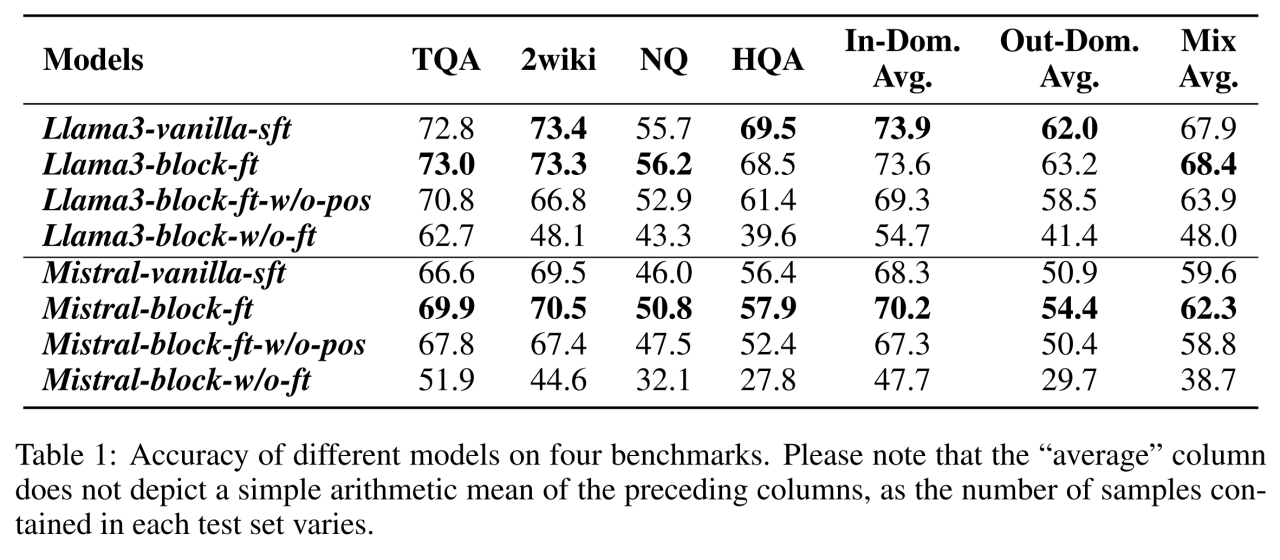
对于问题一,上图给出了答案。作者们根据实验结果给出了三个结论:
1. 直接从 self-attention 切换到 block-attention 是不可取的,因为这会导致准确率急剧下降。例如,对于 Llama3-8B 和 Mistral-7B 模型,去除微调过程会导致在所有四个基准上平均绝对性能下降 21.99%。
2. 然而,如果作者们在微调阶段使用块注意力机制,那么得到的模型与自注意力模型的性能几乎相同,甚至在某些数据集上略好。例如,Mistral-7B-block-ft 在四个基准上的性能优于自回归方式训练的模型,平均准确率由 59.6% 上升至 62.3%。
3. 位置重新编码操作对于 block-attention 模型至关重要。去除它会导致性能显著下降 —— 在四个数据集上准确率平均下降 4%。
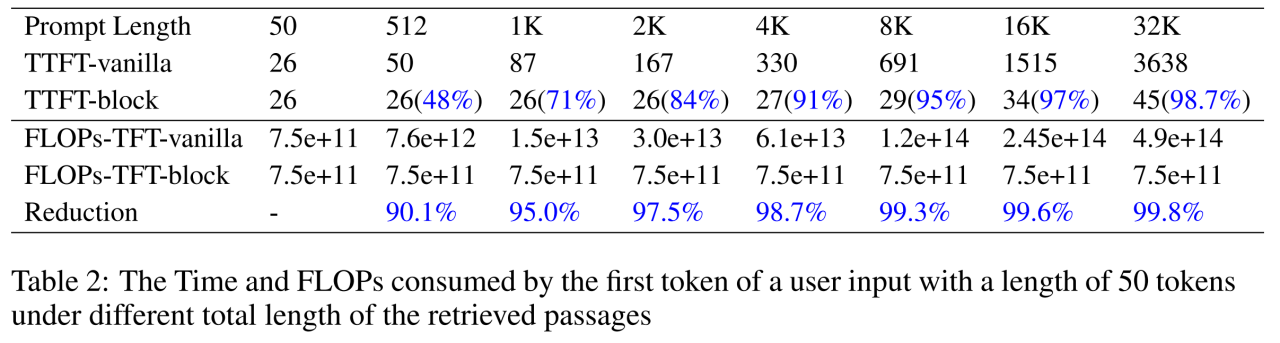
对于效率的提升,作者们也通过另一组实验进行了验证。他们将用户的问题长度固定在 50 个 token,然后逐渐增加被召回文档的数量,让输入序列总长度从 50 一直增加到 32K。模型在不同 prompt 长度下的首字延时(Time To First Token, TTFT)和首字浮点运算数(FLOPs To Frist Token, (FLOPs-TFT)如下图所示。显然,加速效果令人满意:当输入序列的长度为 512 时,使用 block-attention 可以将 TTFT 减少 48%,将 FLOPs-TFT 减少 90.1%。随着总长度的增加,block-attention 模型的 TTFT 和 FLOPs-TTF 保持基本不变的趋势。当总长度达到 32K 时,加速效果可以达到惊人的 98.7%,FLOPs-TFT 的消耗甚至减少了 99.8%。作者们将此实验结果总结为:“文本越长,block-attention 越重要”。
作者们最后还指出,block-attention 在很多场景中都有着重要作用,并不局限于 RAG。由于一些保密原因,作者们暂时无法透露在其他工业应用中是如何使用它的。作者们期待社区的研究人员能够进一步探索 block-attention 的潜力,并将其应用于合适的场景。
