
无限游戏真的实现了。
如果你是一位开放世界或角色扮演游戏的玩家,你一定梦想过一款无限自由的游戏。没有空气墙,没有剧情杀,也没有任何交互限制。
现在,我们的梦想可能真的要开始成真了。
借助大型语言模型和视觉生成模型的力量,谷歌新开发的一个无限制(Unbounded)游戏已经为我们昭示了这一可能性。

Unbounded 一作 Jialu Li 的推文

这个游戏世界是 AI 生成的,并且可随着游戏的推进而无限延展和演进,里面的角色也可根据用户的要求而定制,同时,这个游戏也不存在任何交互规则的限制。一切都是开放的,甚至你的想象力都无法限制它,就像《安德的游戏》中的心智游戏。
电影《安德的游戏》中的心智游戏画面
虽然目前该游戏整体还比较简单,更多的还是进行一种概念验证,但其隐含的可能性却足以引起人们的无限遐想。

谷歌 Unbounded 游戏设计思路的根源可追溯到 1986 年 James P. Carse(詹姆斯・卡斯)的著作《有限与无限的游戏》,其中描绘了两种不同类型的游戏。

在卡斯的定义中,有限游戏是「以获胜为目的的游戏」,它们有边界条件、固定的规则和明确的终点。而无限游戏的「目标是让游戏继续下去」,没有固定的边界条件,规则也会不断演变。
传统的视频游戏基本都是有限游戏,存在计算机编程和计算机图形的限制。举个例子,所有的游戏机制都必须在编程语言中完全预定义,所有图形资产都必须预先设计(模块化程序生成也仍存在结构限制)。这样的游戏只允许一个有限的动作和路径集,有时候这些动作还是预先定义的。它们通常还有预定义的规则、边界条件和获胜条件。
生成模型的发展为游戏带来了全新的可能性。放开脑洞想想,我们甚至可以造出所谓的「生成式无限视频游戏」。
近日,谷歌和北卡罗来纳大学教堂山分校的一篇论文探索了这一可能性,提出了首个交互式生成式无限游戏 Unbounded,其中的游戏行为和输出皆由 AI 模型生成,从而超越了硬编码系统的限制。

论文标题:Unbounded: A Generative Infinite Game of Character Life Simulation
论文地址:https://arxiv.org/pdf/2410.18975
项目地址:https://generative-infinite-game.github.io/
据该团队介绍,Unbounded 的灵感来自《小小电脑人》、《 模拟人生》和《拓麻歌子》等沙盒人生模拟和电子宠物游戏。其还整合了《龙与地下城》等桌面角色扮演游戏的元素,此类游戏能提供视频游戏不具备的无限制讲故事体验。
Unbounded 的游戏机制围绕角色模拟和开放式交互,如图 2 所示。

玩家可以将自己的角色插入游戏,定义自己角色的外观和个性。游戏会生成一个世界,这些角色可以在其中探索环境、与物体互动并进行对话。游戏会根据玩家的行为和选择生成新的场景、故事和挑战,从而创造个性化和无限的游戏体验。下图显示了一些生成游戏示例。

具体来说,Unbounded 具有以下功能:
1. 角色个性化:玩家可以将自己的角色插入游戏,定义自己的外观和个性。
2. 游戏环境生成:Unbounded 会生成一个持久的世界,让角色可以探索和互动。
3. 开放式互动:玩家可以使用自然语言指令与角色互动,并且没有预定义的规则来限制互动。
4. 实时生成:该团队强调了游戏速度的重要性,与初级实现相比,实际游戏实现了 5-10 倍的加速,每个新场景的延迟约为一秒。
为了做到这一点,该团队在语言模型和视觉生成方面都做出了一定的技术创新。
方法介绍
Unbounded 是一款由文本 - 图像生成模型和大语言模型驱动的交互式生成无限游戏。
Unbounded 包括:
(1) 个性化自定义角色:用户创建具有可自定义外观和个性的独特角色;
(2) 动态世界创建:系统生成一个持久的交互式游戏世界供探索;
(3) 开放式交互:玩家通过自然语言与角色互动,游戏根据玩家动作动态生成新的场景和故事情节;
(4) 以交互速度生成:游戏以近乎实时的交互性运行,实现接近一秒的刷新率。
潜在一致性模型
Unbounded 的一个关键特性是它能够为完全基于生成模型的游戏提供实时交互。这是通过使用潜在一致性模型 (LCM,latent consistency model) 实现的,该模型只需两个扩散步骤即可生成高分辨率图像。通过利用 LCM,Unbounded 实现了实时文本到图像 (T2I) 生成,这对于提供刷新率接近一秒的交互式游戏体验至关重要。
具有块丢失功能的区域 IP 适配器
Unbounded 的另一个关键特性是在预定义环境中生成角色,并根据用户指令执行不同的操作。
在游戏领域,保持角色和环境的一致性至关重要,目前来看,角色一致性的处理方式上还存在一些挑战。
该研究发现现有方法无法始终如一地满足所有交互速度要求。因此本文提出了一种新颖的区域 IP 适配器(regional IP-Adapter),以便按照文本提示在预定义环境中始终如一地植入角色。
该研究提出了 IP 适配器的改进版本,该版本能够对主体和环境进行双重调节,从而允许在用户指定的环境中生成预定义的角色。与专注于单图像调节的原始 IP 适配器不同,本文方法引入了双重调节和动态区域注入机制,以在生成的图像中同时表示这两个概念。
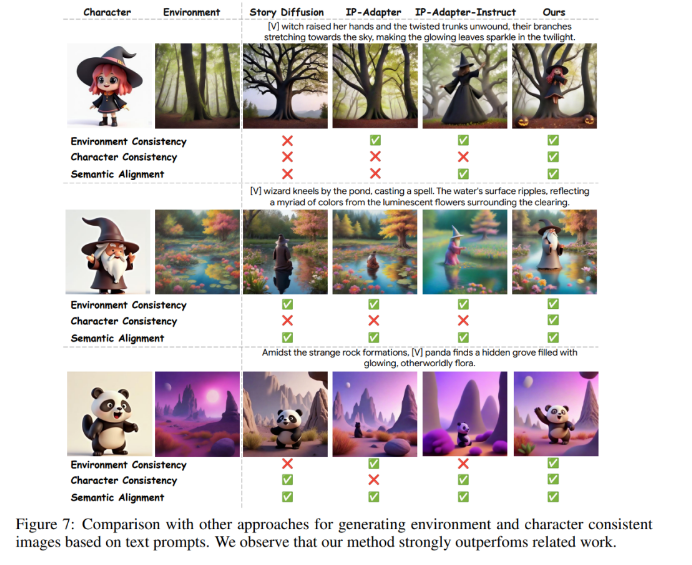
举例来说,如图 4 所示,给定文本提示「天空下的沙漠,女巫让仙人掌绽放出鲜艳、发着光的花朵」和沙漠环境图像,模型需要知道提示中的角色应该在仙人掌旁边,还需要知道仙人掌、花朵在沙漠环境中生成。
这要求模型正确地 (1) 保留环境 (2) 保留角色 (3) 遵循提示。然而利用 IP 适配器对环境进行编码会极大地损害原始图像的特点(图 8 中的 (2) 和 (3))。
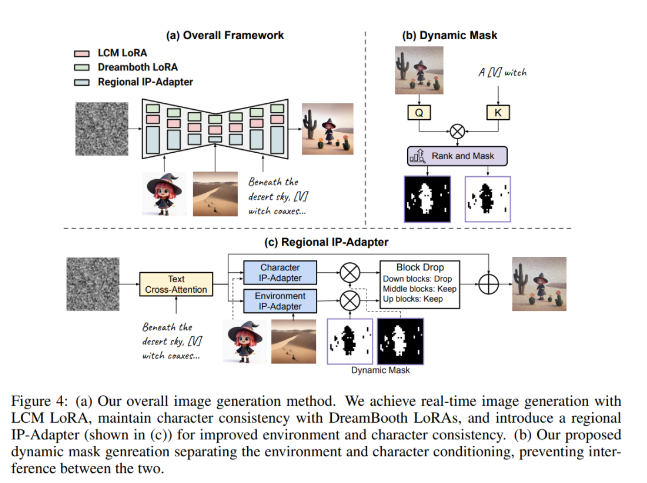

区域 IP 适配器很好的解决了这个问题。具体来说,本文引入了一种基于动态掩码的方法,该方法利用模型每一层的字符文本嵌入和隐藏状态之间的交叉注意力来实现。如图 4 所示,本文方法将适配器分别应用于与环境和角色相对应的区域,防止环境条件干扰角色的外观,反之亦然。
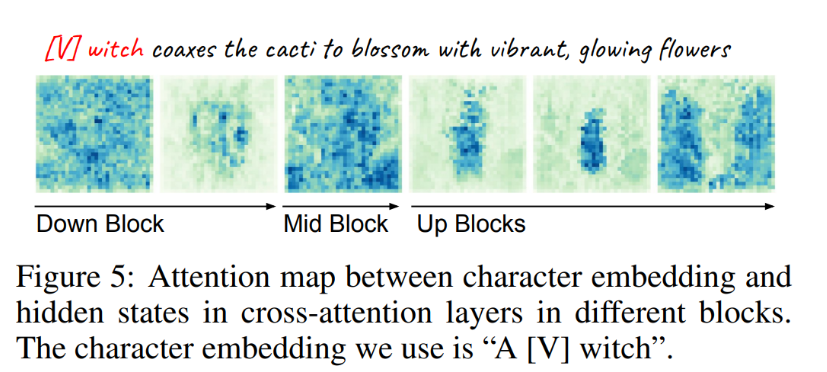
对于区域 IP 适配器,该研究使用字符文本和隐藏状态之间的交叉注意力的动态掩码。此掩码的质量是分离字符和环境生成的关键。图 5 显示了下采样块的交叉注意力层中字符嵌入和隐藏状态之间的注意力图。可以观察到,注意力并不集中在字符上,而是分散在这些块的整个图像上。这表明扩散模型不会在这些层中分离字符和环境生成,而是专注于基于文本提示的整体图像结构。
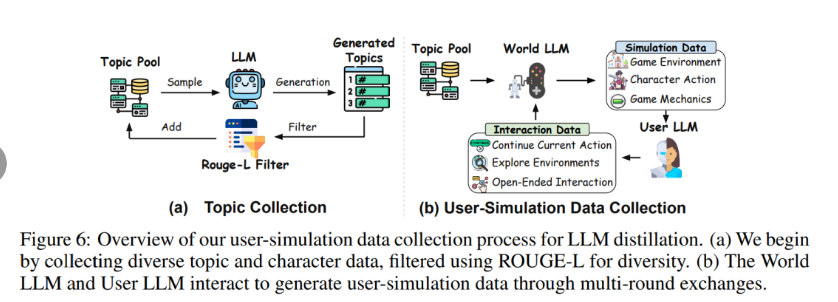
具有开放式交互和集成游戏机制的语言模型游戏引擎
该研究构建了一个角色生活模拟游戏,包含两个 LLM 智能体:
一个智能体充当世界模拟模型,负责设置游戏环境、生成叙事和图像描述、跟踪角色状态并模拟角色行为;
第二个智能体充当用户模型,模拟玩家与世界模拟模型的交互。它有三种类型的交互:在当前环境中继续故事、将角色移动到不同的环境中,或与角色互动。在每种交互类别中,用户都可以选择提供角色的个性细节,或者引导角色的行为,从而影响模拟器的叙事生成。
实验及结果
实验中,该研究使用 GPT-4o 收集了一个由 5,000 个(角色图像、环境描述、文本提示)三元组组成的评估数据集。它包括 5 个角色(狗、猫、熊猫、女巫和巫师)、100 个不同的环境和 1,000 个文本提示(每个环境 10 个)。
环境一致性和角色一致性之间的比较
在该实验中,作者主要将带有块丢失的区域 IP 适配器和此前方法进行了比较。
如表 1 所示,本文方法在保持环境一致性和角色一致性方面始终优于以前的方法,同时在保持语义对齐方面也达到了可比的性能。
具体来说,在角色一致性方面,本文方法在 CLIP-I^C 中显著超过 StoryDiffusion,在 DreamSim^C 中超过 StoryDiffusion 0.057。在环境一致性方面,本文方法也是优于其他方法。
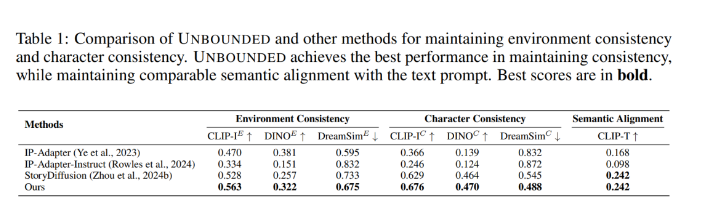
图 7 是与其他方法进行了定性比较。区域 IP 适配器采用块丢失技术,始终能够生成具有一致性的图像,而其他方法可能无法包含角色或生成外观不一致的角色。此外,研究还表明,本文方法能够很好地平衡环境一致性和角色一致性,而其他方法可能会生成与条件环境不同的环境。
带有块丢失的动态区域 IP 适配器的有效性
实验证明,带有块丢失的区域 IP 适配器对于按照文本提示将角色放置在环境中至关重要。
如表 2 所示,添加块丢失可同时改善环境和角色的一致性,CLIP-I^E 中增加了 0.291,CLIP-I^C 中增加了 0.264,同时文本提示和生成的图像之间的对齐效果更好。此外,区域 IP 适配器增强了角色一致性和文本对齐效果,同时保持了环境一致性的可比性能。
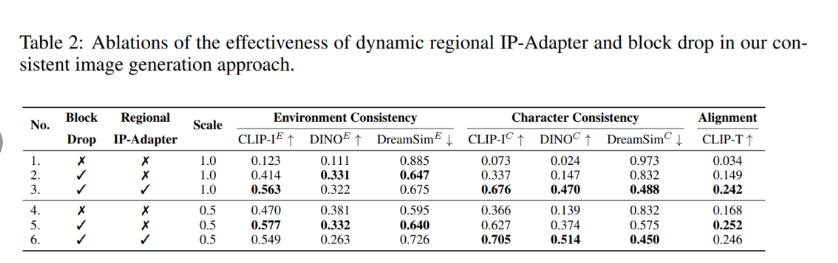
图 8 给出了定性实验结果。可以看到,基于使用 IP 适配器的环境可以实现优良的环境重建,但角色一致性会受到环境风格的影响。

块丢失技术可提升遵从文本提示词的能力,从而让生成的图像中有正确的角色和环境空间布局。不过角色外观仍会受到周围环境的影响。通过将新提出的区域注入机制与新提出的动态掩码方案相结合,生成的图像可实现强大的角色一致性,同时还能有效地考虑环境条件。
蒸馏专业化 LLM 的有效性
实验表明,该团队的多样化用户 - 模拟器交互数据可以有效地将 Gemma-2B 蒸馏成功能强大的游戏引擎。
如表 3 所示,相比于该团队蒸馏得到的模型,在进行零样本推理时,小型 LLM(即 Gemma-2B、Llama3.2-3B)或稍大一些的 LLM(即 Gemma-7B)的表现会差一些,这说明针对游戏世界和角色动作模拟任务而蒸馏更强大的 LLM 是有效的。
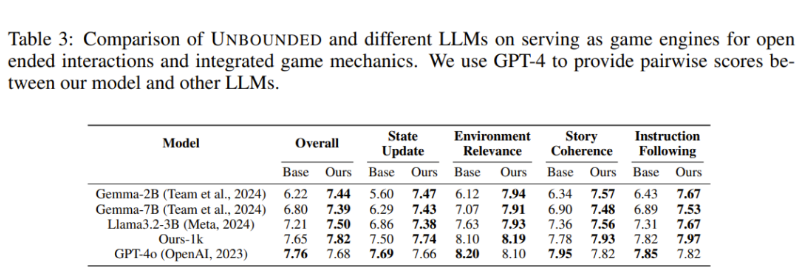
此外,从结果数据上看,这个蒸馏版模型的表现与 GPT-4o 相当,这也足以说明该方法的有效性。该团队还研究了蒸馏数据规模对性能的影响,具体做法就是比较使用 1K 和 5K 数据来蒸馏 Gemma-2B 模型,看结果有何差异。结果没有意外,使用更大的数据集在各个方面都更优。
