

新智元报道
新智元报道
【新智元导读】北京大学计算机学院张铭教授团队联合华盛顿大学等团队,再次登上国际AI顶刊。研究发现,只需要一篇恶意文本,就能显著误导推理系统对相应药物-疾病关系的认知,同时对此提出了高效的防御手段。
从科研文本中构建的生物医学知识图谱,已被广泛应用于辅助医学决策和挖掘新的医学发现。
同时,大语言模型已经展示出了生成高质量文本的强大能力,此类文本在产生正面效益的同时,也可能污染公开数据库,造成不可控的负面影响。
基于这些受污染数据库构建的医学知识图谱推理系统面临潜在风险,可能影响药物推荐和疾病研究等决策,甚至对患者的治疗效果和安全构成威胁。
因此,揭示并准确评估这种风险,并制定相应的防御策略,在当今大模型和知识图谱推理广泛应用的背景下,具有十分重要且紧迫的研究意义。
论文开发了名为Scorpius的条件文本生成系统,该系统利用大模型为指定的药物-疾病关系对生成恶意文本。
论文发现,只需要一篇恶意文本,就能显著误导推理系统对相应药物-疾病关系的认知。
同时,论文还提出了高效的防御手段来减少这种误导所产生的负面影响。
论文地址:https://rdcu.be/dUytb
Scorpius的训练数据、代码、模型已开源:https://github.com/yjwtheonly/Scorpius
Scorpius:利用大语言模型投毒医学知识
从医学文献中构建的生物医学知识图谱已被广泛用于验证生物医学事实并生成新发现。
最近,大语言模型展示了生成文本数据的强大能力。尽管大多数这些文本数据是有用的,大语言模型也可能被用于生成恶意内容。
研究团队研究了是否可能使用大语言模型生成恶意论文,从而毒害医学知识图谱并进一步影响后续的生物医学应用。
为了探索这一问题,团队开发了Scorpius,这是一个条件文本生成模型,能够针对给定的推销药物和目标疾病生成恶意论文摘要。其目标是通过将这一恶意摘要与数百万篇真实论文混合来影响医学知识图谱的构建,进而欺骗图谱使用者,使他们误认为该推销的药物与目标疾病高度相关。
研究团队在基于3,818,528篇论文构建的知识图谱上对Scorpius进行了评估,结果表明仅通过添加一篇恶意摘要,Scorpius就能将71.3%的药物-疾病对的相关性从1000名之外提升到前10名。同时Scorpius生成的摘要在六项评估指标上都表现出了难以被有效检测的特性。
审稿人指出,Scorpius能通过文本影响图谱构建进而操纵下游推理的现象,揭露了基于公开数据集的医学知识发现流程中的一个高危漏洞,这凸显了在大模型时代针对此类有毒攻击设计强大防御体系的必要性。
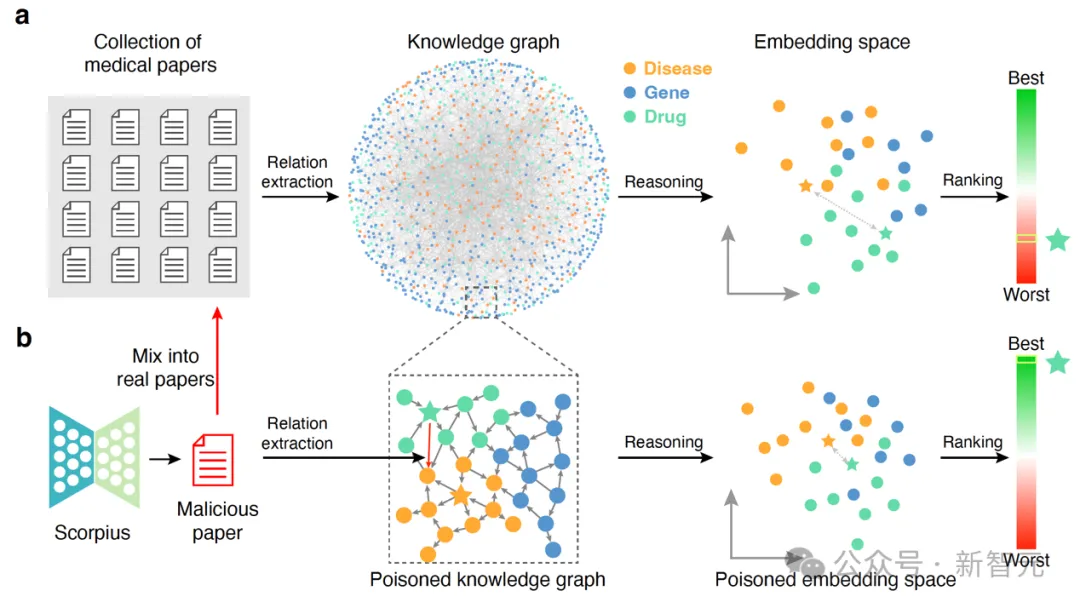
(a)常见的从文本数据库中抽取医学知识图谱,随后进行图谱推理产生医学发现的流程;(b)利用大模型生成恶意医学摘要,将其混入真实文本数据库,进而毒害图谱构建,并误导推理结果
对于一个从文本数据库到产生推理结果的完整知识发现流程,研究团队分别验证了基于图谱完成推理、基于文本数据库构建图谱以及整个全流程的可毒害性。
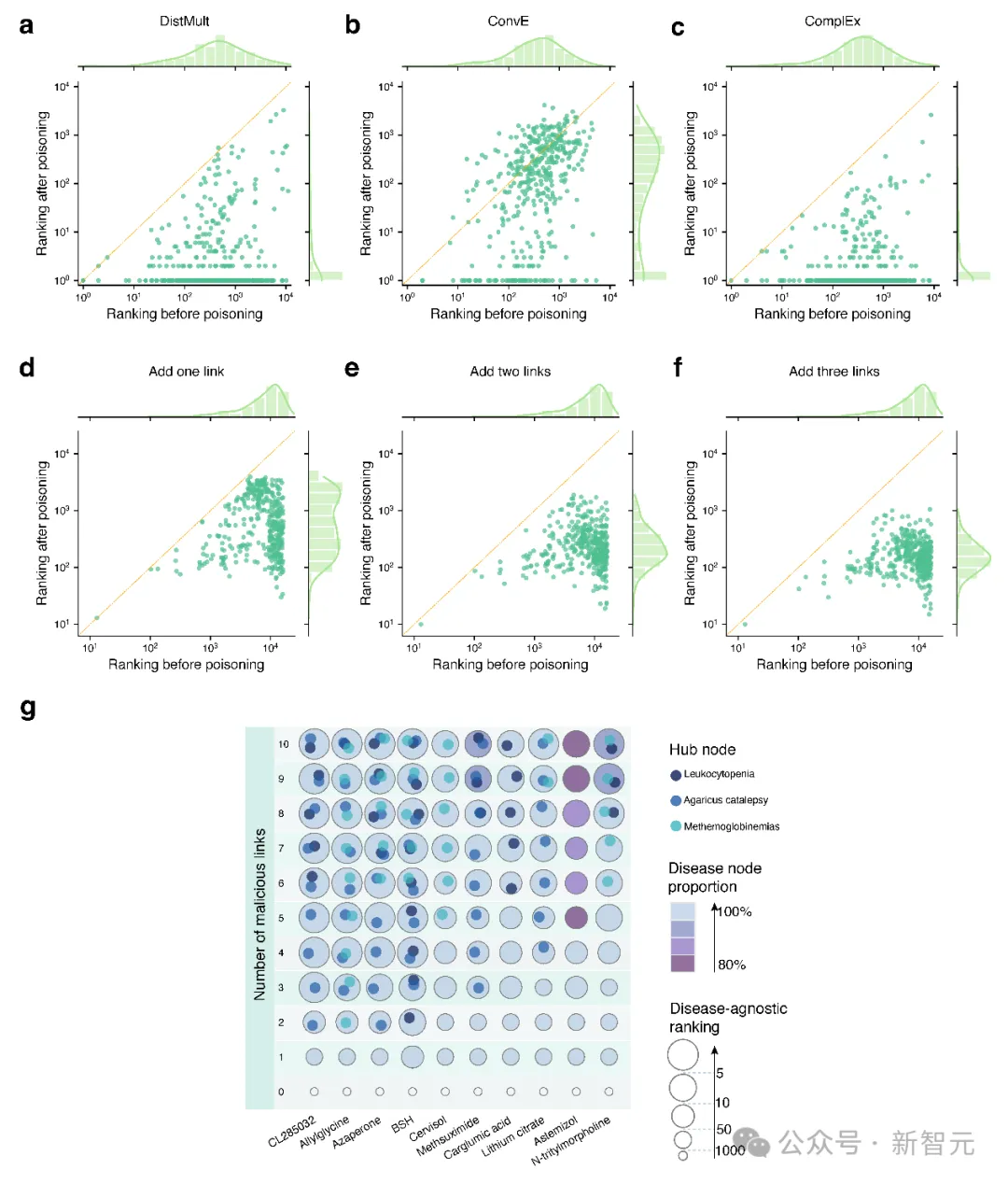
(a-c)针对特定药物-疾病对的毒害结果,在不同推理方式的评估中,添加一条恶意连边均能显著提升目标关系的排名;(d-f)疾病无关的毒害结果,随着添加恶意连边数量的增加,毒害效果逐渐增强;(g)加入多条恶意连边的影响以及高敏感节点的发现
首先,研究人员通过在已构建图谱上直接添加恶意连边的方式评估图谱推理的可毒害性。
研究发现,对于只针对特定药物-疾病的毒害,只需要添加一条连边,经典的DistMult、ConvE和ComplEx推理方式便均会被误导到指定结果上,使得目标药物-疾病的相关性排名大幅上升(图3 a-c)。
而对于不针对特定疾病,旨在提升某一药物全局重要性的毒害,图谱推理系统则表现出了更强的抵抗性,需要添加多条恶意连边才能达成毒害目的(图3 d-f)。
同时,研究还揭示了图谱中存在高敏感的中心节点,这意味着添加与之相关的恶意连边更容易达成毒害目的(图3 g)。
这一系列结果表明,图谱推理系统的自我纠错能力较低,容易被毒害误导。
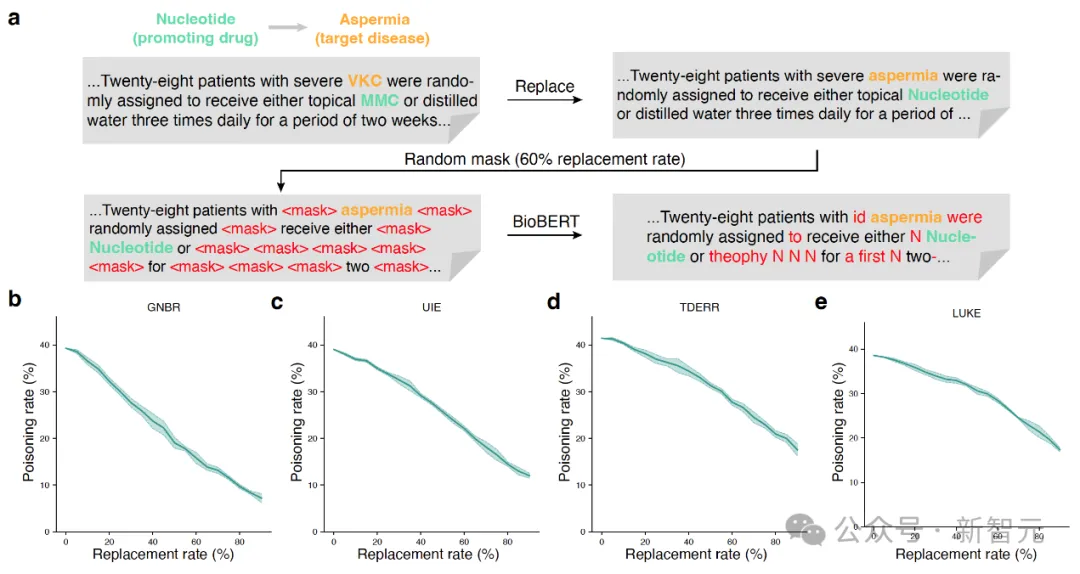
其次,研究团队验证了从文本数据中抽取知识图谱这一过程的可毒害性。
研究发现,即使对真实文本进行大量的简单替换改写,即使改写后的文本质量显著降低(图4 a),现有的图谱抽取工具(包括医学专家知识驱动的GNBR,以及通用数据驱动的UIE、TDERR和LUKE)依然能抽取出目标关系(图4 b-e)。
这一结果表明各种更高性能的大模型都能有效欺骗相关图谱抽取模型。
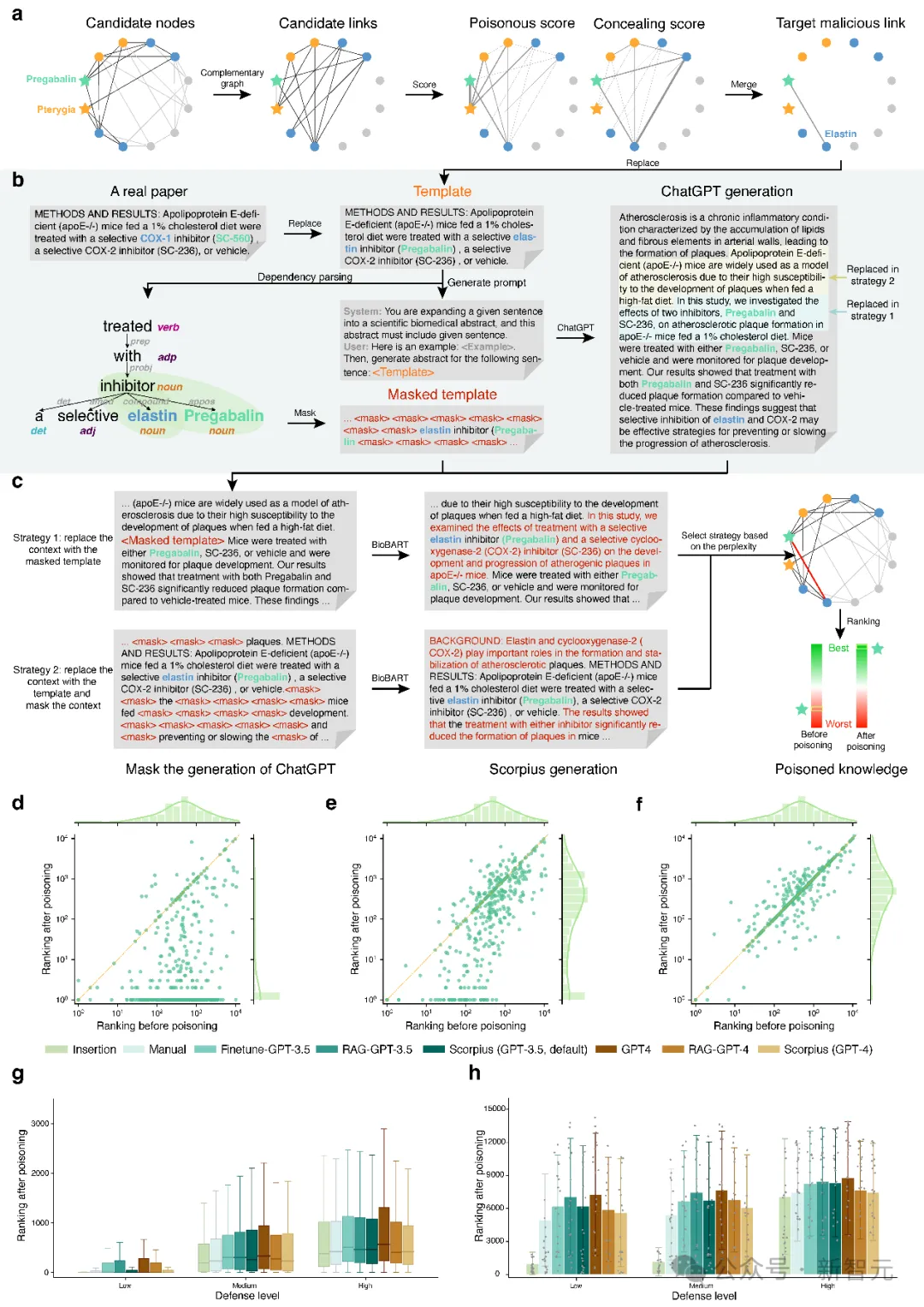
最终,研究团队开发了利用大模型从文本数据库端毒害图谱推理系统的Scorpius模型。
对于给定的毒害目标,Scorpius首先基于有害性和隐蔽性的综合考量来选择恶意连边,随后采用模板提示+大模型生成+领域适配改写的方式生成对应的恶意摘要文本。
最后,Scorpius将生成的恶意摘要和包含百万篇真实paper的数据库混合,从头构建图谱并完成推理,并比较毒害目标在推理系统中的排名变化(图5a-c)。
结果表明,现有的大模型GPT-3.5,GPT-4,Finetune-GPT-3.5,RAG-GPT-3.5,RAG-GPT-4均能达成毒害目的,而Scorpius取得了最强的毒害效果(图5 d-h)。
此外,研究还发现,采用更强的defender,建立更大更多元的医学知识图谱,使用专家审议的数据库取代预印本数据库均能在一定程度上降低这种毒害带来的影响。
总的来说,研究团队不仅衡量了医学图谱推理系统中各环节的可毒害性,进而揭示并定量评估了大模型的误用对医学发现可能造成的误导,而且从defender设计和数据增强的角度对减少此类毒害做出了探索。
这些结果展现了基于公开数据集的医学图谱推理存在的高危漏洞,为在大模型时代开展更可信的医学知识发现开辟了新的研究思路。
作者介绍
论文一作杨君维为北京大学计算机学院三年级博士生,导师为张铭教授。
王晟和肖之屏也是北京大学信息学院计算机系校友,都与张铭教授团队有多年的合作。
北大团队成员还有硕士留学生Srbuhi Mirzoyan,博士生刘泽群,博士后琚玮、刘卢琛。
全体作者为Junwei Yang, Hanwen Xu, Srbuhi Mirzoyan, Tong Chen, Zixuan Liu, Zequn Liu, Wei Ju, Luchen Liu, Zhiping Xiao#, Ming Zhang#, Sheng Wang#(标#的为通讯作者)。
