
【新智元导读】中科院北大复旦大佬齐聚的2024科学智能峰会,刚刚在位于北京海淀的北大百年纪念讲堂落下帷幕,现场演讲信息量爆棚。同期,海淀这片创新热土还有好消息传出:海淀区送算力补贴了,最高1000万!
全世界大模型卷了一年多,AI已然成为科技博弈中最为关键的领域。
恰在11月4日,「2024科学智能峰会」在北京海淀召开。
海淀区,作为中国AI硅谷,凭借丰富资源和多元化政策支持,吸引着越来越多科研、技术、人才。
这场峰会可谓星光熠熠,汇聚了中国科学院、北大、复旦等顶尖机构的学术大咖。
他们齐聚一堂,围绕AI在科学研究中应用及未来展开深入讨论。
从物理、化学到生命科学,AI全面革新
在北京大学百年纪念讲堂,来自不同领域的顶尖科研专家们,共同探讨了AI技术在量子计算、生命科学、材料研究、高性能计算等多个领域的应用。

在物理学领域,中国科学院院士、复旦大学教授龚新高详细阐述了量子力学与分子动力学之间的联系,并探讨了如何借助机器学习和人工智能技术优化材料设计流程。物理学已经从传统的实验物理、理论物理发展到计算物理,并且现在正迈向由人工智能赋能的数智物理时代。
在生命科学领域,中国科学院院士、北京大学-清华大学生命科学联合中心主任汤超表示,「AI for Life Science至少有四个元素,除了数据、算力、算法以外,还有原理。通过AI继续寻找和嵌入生命科学的基本原理是关键」。
材料科学方面,中国科学院院士、博雅讲席教授张锦介绍了,在材料表征、材料制备、与产业化等方面AI革新材料研究范式的例子与思路。他认为,「AI这个工具不仅可以得到认知的扩展,辅助决策,也会放大人的创造力」。
在化学与材料的交叉学科中,中国科学技术大学讲席教授江俊具体分享了一些具体的机器化学家平台应用实例,并指出,「AI for Science通过数据智能的方法,为弥补理论和实践的鸿沟提供了可行的路径」。

2024科学智能峰会不仅是一次学术交流盛会,更是推动AI与科学研究结合的一个节点。
海淀,正通过自身独特创新生态和政策支持,逐渐把AI推向新的高度。
「中国硅谷」的AI布局
在AI布局上,海淀区正形成一个繁荣的AI生态链。
今年4月中关村论坛上,海淀正式宣布了打造具有全球影响力「人工智能创新策源地和产业高地」。
在这430.7平方公里的地方,聚集了人工智能所有的基础要素。
不论是在AI企业数量、高校机构,还是数据要素资源、产业链、算力建设等方面,海淀都走在了最前列。
如今,在AI领域深耕布局已久的海淀,已经取得一系列丰硕成果,成为名副其实的「中国硅谷」。
1.23万顶尖人才聚集
现在,海淀已经吸引了北京市超八成以上的人工智能学者扎根,共有1.23万人。而位于人工智能领域TOP 2000全球顶尖科学家,就有101人次。
在科研实力和教育资源方面,海淀区汇聚了以清华、北大、中国科学院为代表的37所高等学府,获批AI本科的高校有21所。
96家科研院所,31个国家工程研究中心,52个全国重点实验室,106个国家级科研机构。
其中,有人工智能领域全国重点实验室14家,新型研发机构3家。
这些高校和研究机构,为人工智能的产业发展,能够输送源源不断的人才,提供了丰富的沃土、创新的动力。
AI企业1300+,大模型备案66款
就产业聚集来看,百度、旷视、百川智能、智谱华章等1300多家AI企业扎根于海淀发展。
其中大模型企业超百家,26家企业被定位为独角兽企业,备案大模型66款。
数据显示,海淀发布大模型、备案上线大模型数量占全市七成、全国近三成,形成覆盖人工智能芯片、框架、大模型等的全链条布局,并在全国率先形成了AI大模型产业聚集区。
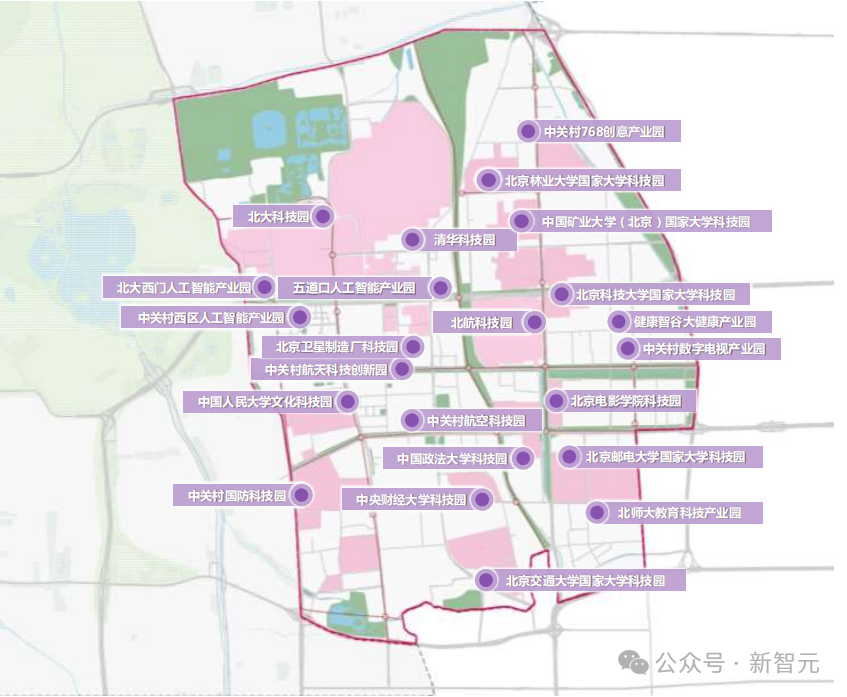
海淀打造人工智能创新街区
另据科技部发布的《中国人工智能大模型地图研究报告》显示,北京在大模型学者指数、模型开源数量和影响力等指标上,均为全国首位。
政策全面支持
在此基础上,海淀区政府再次颁布一系列政策,进一步巩固海淀在全球科技竞争中的领先地位。
2024年,一盘围绕「AI+」的大棋正缓缓铺开,一系列的政策支持不断为海淀企业营造出一个营商环境优良、鼓励科研创新、吸引尖端人才的优质生态环境:
4月《关于打造全国具身智能创新高地三年行动方案(2024-2026年)》发布;
8月《中关村科学城人工智能全景赋能行动计划(2024-2026年)》和《海淀区“人工智能+教育”三年行动计划(2024-2026年)》发布;
9月《中关村科学城发布人工智能全景赋能首批开放场景榜单》发布。
其中,《行动方案》重点聚焦的是具身大模型和机器人整机。力争到2026年初步建成全国具身智能原始创新策源地、应用示范高地、产业加速聚集地。
而在《行动计划》中,海淀区将以人工智能创新街区为主要阵地,率先打造出国内首个AI应用加速器,将中关村科学城打造为AI全景赋能第一城。
而《人工智能全景赋能首批开放场景榜单》则以首批十个开放场景为示范,如具身智能、文旅消费、教育教学等,来推进《行动计划》的落实。
通过深入挖掘场景需求,广泛征集解决方案,打造试验场平台,实现供需高效对接,共同探索AI创新应用、经济社会高质量发展的新模式。
这一次,为了助力企业突破算力瓶颈,进一步加速AI创新应用,「中国硅谷」海淀发布了算力补贴政策,进一步加速AI创新和应用。
为什么补贴?
原因很简单——AI的训练和部署,是一个算力的黑洞。
通往AGI大模型,还需无尽算力
业界普遍认为,通过增加算力和数据来扩大AI训练规模,是开发更强大AI模型的关键。
今年10月,马斯克为自家大语言模型Grok准备的全球最大AI超算Colossus正式完成部署,共配备有10万块NVIDIA Hopper GPU。随后,xAI还会将规模扩大一倍——达到20万块GPU。

同在10月,Meta首席执行官扎克伯格宣布,下一代旗舰模型Llama 4的训练,正在一个拥有超过10万块H100的集群上全速推进——规模超过了目前任何已知项目。
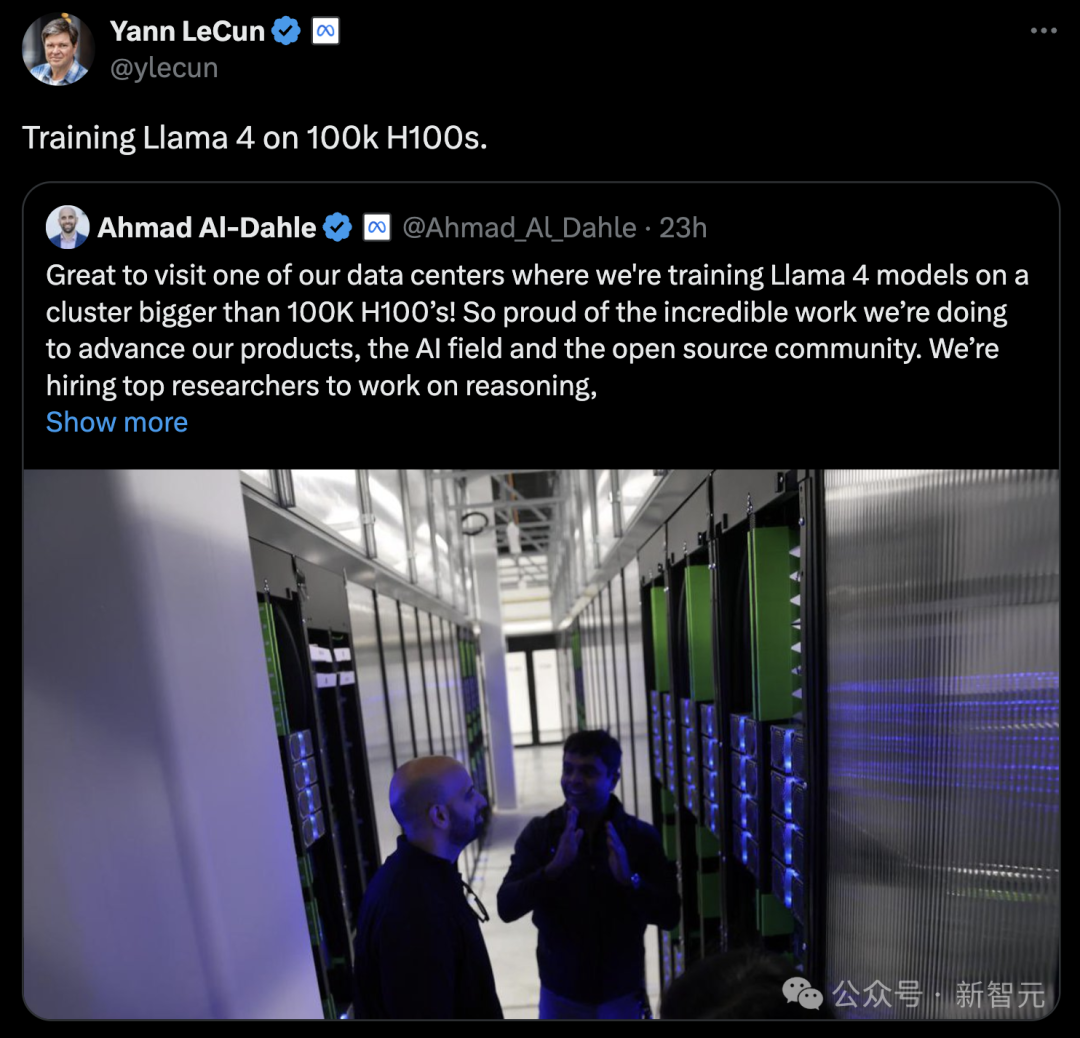
与此同时,OpenAI也将在2026年之前,获得微软提供的多达30万块英伟达AI芯片的使用权。
从他们身上可以看到,算力战略地位的重中之重。
如今,这片诞生了中国互联网的土地上,海淀区政府还要再点一把火,助力中国大模型企业加速进入新的腾飞!
算力贵?政府补!最高1000万
提起在海淀区的明星企业,从业者们都是如数家珍。
从21世纪前两个十年就诞生的百度、小米、美团、字节跳动、快手,到最近几年纷纷崛起的寒武纪、百川智能、智谱华章、月之暗面、零一万物等等,一个个企业从中关村走向全国、走向世界。
可是,市面上更多的是体量较小、起步慢、资金实力有限的中小企业,如果因为算力的短缺,就无法搭上大模型的这趟列车,岂不遗憾?
好在,海淀区政府出手了!
中小企业是创新和活力之源,更是我国民营经济的重要组成部分;他们所需要的,是一个帮他们做大模型落地的第三方。
如果由这个第三方提供资金支持、建立产业合作平台、完善政策法规,甚至还能提供计算资源支持,那么大模型的落地无疑就会加快很多。
在美国,这个第三方往往是企业;而在中国,这个第三方是政府。
近日,海淀政府发布的算力补贴专项申报指南中,详细给出了具体的申报标准和要求。
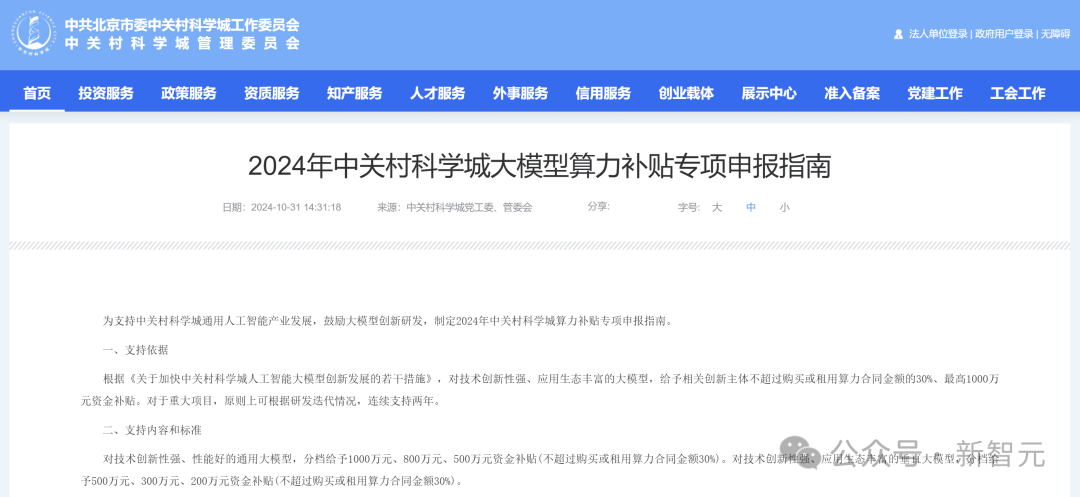
https://www.bjhd.gov.cn/qyfw/bulletIndexDetail/1851875069950918656?type=zhina&hasBack=false
对技术创新性强、性能好的通用大模型,分档给予1000万元、800万元、500万元资金补贴。
对技术创新性强、应用生态丰富的垂直大模型,分档给予500万元、300万元、200万元资金补贴。
与此同时还要满足,给予相关创新主体不超过购买或租用算力合同金额30%。
对于重大项目,原则上可根据研发迭代情况,连续支持两年。
那么,什么条件的项目,能够进行申报呢?
毋庸置疑,首先是在海淀区注册的独立经营实体,才有资格参与这次算力补贴。
其次,申报企业需提供购买或租用算力合同、发票及算力用于大模型研发的相关证明材料。
接下来的条件,是关于具体在模型申报方面的要求。
企业只能在通用/垂直大模型中选择一类进行申报,并提交模型自评或第三方评测报告(包括但不限于模型理解、推理、生成能力及智能性、鲁棒性、效率等)。
对于通用模型的申报,还将交由统一组织的第三方机构进行评测,最终根据专家评审分数和模型评测分数综合定档。
而垂直大模型在符合以上所有基础上,还要完成了研发并对外提供开放服务,最终根据专家评审分数模型评测分数综合定档。
(注意:具体组织方式和评测范围另行通知)
11月14日前,企业可通过专项资金平台报,按要求填写基本信息并提交《中关村科学城算力补贴专项申报书》及有关附件材料完成申报。
可以看出,海淀区政府下了决心,要真正帮中小企业在内的千行百业落地大模型。
在算力方面,海淀区正在积极打造北京人工智能公共算力平台,向区内多家重点创新公司提供算力服务。
而这次的支持,则更为直接——给企业提供通用/垂直大模型的补贴!
另外,数据方面企业也不用着急。
海淀区已经积极推动了北京人工智能模型语料中心建设,现在已经有超过140个高质量数据集(PB级),向大模型企业提供了。
相当于是,大模型的三板斧「数据、算法、算力」,企业只需要把算法搞好,剩下两个海淀区都帮忙解决了。
杀手级应用未出现,企业还缺什么
在2024年这个业内公认的大模型应用元年,大模型应用已经逐渐进入深水区。
但是目前,显然「杀手级」的大模型应用仍未出现。
原因在于,在现阶段,大模型垂直行业应用的专业性和门槛仍较高,还需要高质量和广覆盖度的行业数据,仅靠在通用大模型基础上做简单微调,是无法满足部分场景的。
应用场景和技术能力之间的鸿沟,导致了大模型应用落地的阻碍。
只靠有场景的传统行业或有技术的科技公司「自驱」是不行了,市场亟须打破场景、技术双方壁垒的第三方「外力」。
如今,海淀区政府亲自上阵,来打破这种鸿沟!
通过引导联合研发、提供高质量数据、算力扶持等手段,一种全新的「需求-技术-产品-应用」产业闭环,就此形成了。
综上不难看出,在这场全球AI竞争的大潮中,海淀区正以实际行动,展现着「中国硅谷」的担当与魄力。
从产业链、科研实力到基础设施,海淀区正打造一个全方位的AI创新生态系统。
通过基础模型的底层创新,垂类模型将大力赋能实体工业和经济,打造这个时代的新质生产力。
可以预见的是,在这片沃土之上,一个充满活力的AI未来正加速到来
