随着科技的飞速发展,人工智能(AI)在各个领域都取得了显著的进步。然而,尽管深度学习技术已经取得了巨大的成功,但其局限性也日益凸显。为了克服这些局限,类脑计算作为一种可能的解决方案,正在逐步成为AI研究的新热点。本文将介绍深度学习技术的局限性,并探讨类脑计算如何模仿人脑的结构和功能来增强AI的智能水平。
深度学习技术的局限性
深度学习作为当前AI领域的核心技术,其成功在很大程度上依赖于大量的标注数据和强大的计算能力。然而,这种技术也存在一些明显的局限性:
1、数据依赖性:深度学习模型通常需要大量的标注数据来进行训练。在一些特定领域,如医疗图像分析,获取足够的标注数据可能非常困难和昂贵。此外,模型的性能很大程度上依赖于训练数据的质量和多样性。
2、可解释性和透明度:深度学习模型,特别是深层神经网络,通常被认为是“黑盒”模型,其决策过程难以理解和解释。这一点在需要高度透明和可解释性的应用中,如金融服务和医疗诊断,可能构成严重的局限性。
3、计算资源需求高:训练深度学习模型通常需要大量的计算资源,包括高性能的GPU和大量的内存。这不仅增加了研究和开发的成本,也限制了深度学习技术在资源受限的环境中的应用。
4、过拟合的风险:深度学习模型因其复杂性而容易发生过拟合,即模型在训练数据上表现良好,但在未见过的数据上表现不佳。虽然可以通过正则化、数据增强等技术来缓解过拟合,但这仍是一个需要注意的问题。
5、泛化能力:深度学习模型在特定任务上可能表现出色,但它们的泛化能力仍然是一个挑战。模型可能难以应对实际环境中的变化,如不同的光照条件、视角变化或其他未在训练数据中覆盖的场景。
6、安全性和对抗性攻击:研究表明,深度学习模型可能对对抗性攻击特别敏感,即通过微小的、人眼难以察觉的输入变化来误导模型做出错误的决策。这对于安全性至关重要的应用(如自动驾驶车辆)构成了潜在的风险。
7、伦理和偏见问题:深度学习模型可能会从其训练数据中学习和放大偏见,导致不公平或歧视性的决策。
类脑计算:一种可能的解决方案
类脑计算是生命科学,特别是脑科学与信息技术的高度交叉和融合。它借鉴生物大脑的信息处理方式,以神经元与神经突触为基本单元,从结构与功能等方面模拟生物神经系统,进而构建“人造超级大脑”的新型计算形态。
与深度学习相比,类脑计算具有以下优势:
1、低功耗:人类大脑的功耗非常低,仅有20瓦左右,远远低于现有的计算系统。类脑计算通过模仿人脑的结构和功能,有望实现类似的低功耗特性。
2、强容错性:即使少部分神经元死亡,对大脑的整体功能影响不大。类脑计算系统也具备类似的容错性,能够在部分组件失效时继续正常工作。
3、并行处理能力:分布于大脑各处的数百亿神经元可同时对信息进行分析处理。类脑计算系统通过模拟这种并行处理能力,可以显著提高计算效率。
4、可塑性:人类大脑神经网络的可塑性好,可根据环境变化进行自我学习与进化。类脑计算系统也具备类似的自适应学习能力,能够不断根据新数据进行优化和调整。
为了实现类脑计算,研究者们正在从多个方面进行探索:
1、类脑芯片:类脑芯片是建造类脑计算机最关键的部件,它负责模拟大脑神经元的功能特性、信号传递和学习方式。通过探索合适的材料、器件和电路层面,研究者们正在逐步构建出能够模拟大脑神经元和突触的类脑芯片。
2、脉冲神经网络:脉冲神经网络(SNN)是一种新型的神经网络架构,它模仿生物神经元之间的脉冲信号传递方式。与深度学习中的卷积神经网络等架构相比,脉冲神经网络在处理时序信息和稀疏数据方面更具优势。
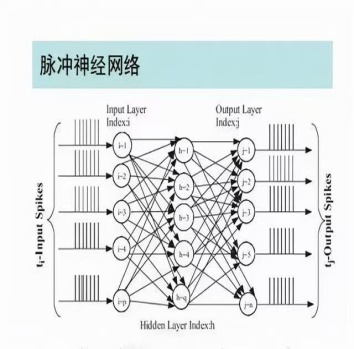
3、算法与系统集成:在类脑计算中,算法与系统集成同样重要。研究者们正在开发新的算法来优化类脑计算系统的性能,并将其应用于实际场景中。同时,他们也在探索如何将类脑计算系统与其他计算架构进行集成,以实现更高效的数据处理和智能应用。
综上所述,深度学习技术虽然取得了显著的进步,但其局限性也不容忽视。类脑计算作为一种可能的解决方案,通过模仿人脑的结构和功能来增强AI的智能水平。随着神经模型、学习算法、类脑器件、基础软件和类脑应用等方面不断取得突破,类脑计算将迎来更为蓬勃的发展态势,为构建“人造超级大脑”带来希望。

